

In this article, my job is to explain the concept of data cleaning in the simplest form. You will learn about what causes unclean data, why it’s so important to get your data cleaned, the processes involved in data cleaning, and some important tips to follow when performing data cleaning tasks.
What is data cleaning?
“Data cleaning is the process of identifying and correcting (or removing) errors, inconsistencies, and missing values in a dataset. It is a crucial step in the data wrangling process and is typically performed before data analysis to ensure the data quality is high, preserved, and can be used effectively.”
What causes unclean data?
Unclean data or data errors and inconsistencies can be caused by a number of things which include, but not limited to:
Human errors
Inaccurate data entry
System faults, and
Old or wrong data
Data cleaning techniques can be as simple as spelling checks and record duplication removal or as complex as imputing missing data and finding and correcting anomalies.
Why is it important to get your data cleaned?
The goal of data cleaning is to improve the quality of data and make it more useful for analysis. A well-cleaned dataset will be more accurate, consistent, and reliable, which can lead to more accurate and reliable results in data analysis.
Practical implementation of data cleaning techniques
For some reason, data often contain missing values and outliers. Outliers are not always wrong so we have to deal with them with optimal care in order not to obtain a false result from our analysis. I will demonstrate some data cleaning processes with some illustrations and examples to enable you to understand the concept of data cleaning easily.
Let’s say you are handed a customer dataset for spend-data profile analysis showing the first ten records as shown in the table below:

Obviously, the data looks unclean in the sense that some missing values and outliers can be spotted.
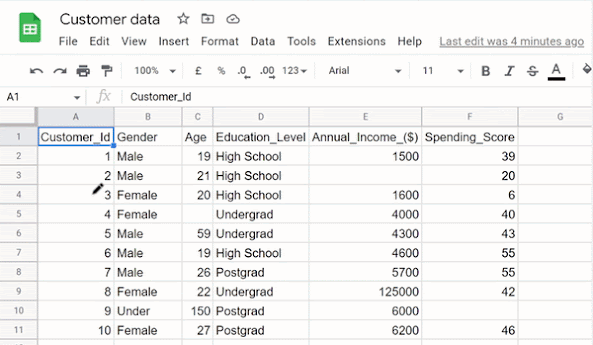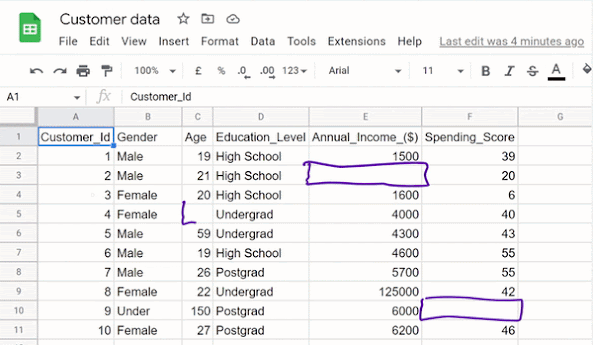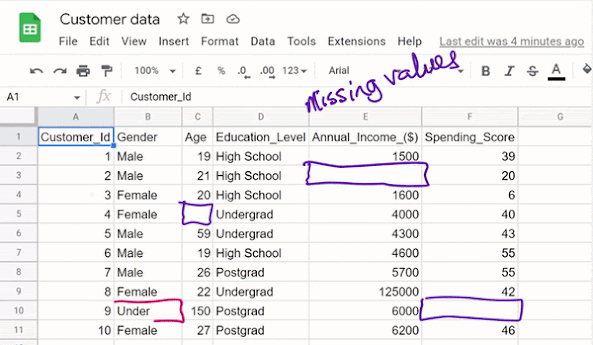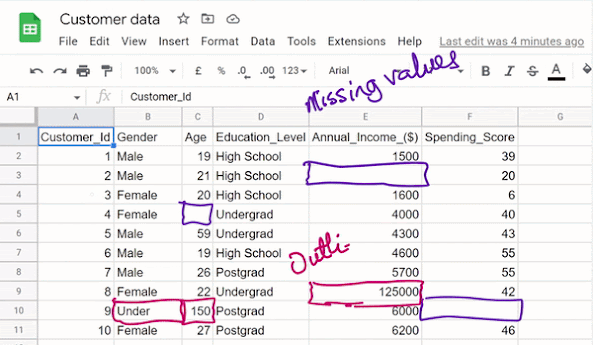
I will walk you through the steps of getting this data clean with the aim to help you understand all the procedures involved in the data cleaning process. Let’s work with the flow chart provided below as a guide in dealing with missing values, outliers, inconsistencies, and whatnot.

Assuming you are looking at a particular cell in your dataset, the first question you will need to ask yourself is; Is that cell empty?
Identifying the outliers

If it’s not, you can move on to determine if it’s an outlier. As the name suggests, an outlier is a value that is significantly different from the other values in a dataset. Outliers can have a significant impact on statistical analyses since they can skew the results (i.e. throw the result off balance) and give a misleading picture of the data. There are a number of ways to identify outliers in a dataset, such as using statistical tests or visualization techniques (these techniques will be discussed in future posts). It is important to carefully examine outliers and consider whether they should be included in the analysis, as they may represent errors or unusual observations that do not reflect the underlying pattern in the data.
Dealing with the outliers

Let’s continue with our flow chart, if the number is not an outlier, then you leave it that way. If you think that the value is an outlier, you then need to decide if it’s obviously wrong. If it is, replace such value with a blank, that is, you delete the value. However, if the value is definitely an outlier because it looks different but we can’t be sure that the value is obviously wrong, then we do what is known as “marking the observation”. Marking means taking a record of which values we believe to be suspicious, in this case, an annual income of $125,000 compared to the annual income of other undergrads of about $4000 is extremely high and certainly an outlier but it’s not impossible that that might happen. Marking could be a written note, a little mark next to each row or you could add it to a list of marks kept on a separate table, you are at liberty to do whatever is cool with you. The idea is that if you continue with such data and obtain a result that seems fishy, you can consult the list of marked observations and see if they were responsible.
Dealing with missing values

Now, let’s see how to deal with the blanks. The first consideration to make here is an important one. We look at the rest of the values in the row in question, and if they are too many missing values we need to get rid of the entire row. You can choose a threshold depending on the project you’re working on, 40/60 is not a bad idea. This means that if 40% and above of the records in a particular row are missing, you can delete the entire row. Here, we have a row of 6 features, 3 of which are blank which represents about 50% of the records in that row. Based on our set threshold of 40%, it is only reasonable that we delete that row completely.
Note: Same can be applied while working with columns.
Why do we delete rows/columns with too many missing values? You may want to ask. The simple answer is that we don’t want too many made-up values in our dataset so we can maintain the data integrity since the next step is to fill up missing values with some summary statistics.
Finally, if the row contains just a small portion of the missing values, we can carry out the imputation process as follows:
- If the feature contains numerical data, a common solution is to fill up the missing values with the mean or average of that feature. For example, in our dataset, the income feature is numerical, so we fill up the missing values with the mean as shown below:
- If the feature is however categorical, we can fill the missing values with the mode of the feature. The mode is the most occurring category of the feature. If we were looking at the feature detailing the highest level of education of a group of people and the most common category there was "High school", we could fill in any blanks in the level of education with "High school".

There are a few things to note here:
- Since the mean is highly sensitive to high or low outlier values, in the instances where you need to impute a numerical value for a feature that may still contain legitimate outliers, like annual income in our example, it may be more appropriate to use something like the median because the median is robust to outliers (i.e. it is not affected by outliers).
- Sometimes overall mean or median is not appropriate, for example, if you needed to impute someone's annual income but that person’s highest level of education was high school, taking the mean or median salary of everyone in the whole dataset wouldn’t be very helpful.
- It might be better to use the mean or median of a small subset of the data, i.e. filling missing values with the mean or median of a group more representative of the row in question. Although, this step can be tedious and time-consuming, but it is worth it.

No comments:
Post a Comment